Decoding patterns and meaning in biological data

Senior Anna Sappington found her perfect balance of “innovative computer science and innovative biology” as a member of the team mapping every cell in the human body.
Raleigh McElvery
When Anna Sappington was six years old, her parents gave her a black and white composition notebook. Together, they began jotting down observations to identify the patterns in their wooded backyard near the Chesapeake Bay. How would the harsh winters or the early springs affect the blooming trees? How many bluebirds nested each season and how many eggs would they lay? When would the cicada population cycle peak? Her father, the environmental scientist, taught her to sift through data to uncover the trends. Her mother, the journalist, gave her the words to describe her findings.
But it wasn’t until Sappington competed in the Intel International Science and Engineering Fair her junior year of high school that she probed one tiny niche of the natural world more keenly than she ever had before: the physiology of the water flea. Specifically, she investigated the developmental changes that these minute creatures experienced after being exposed to the antimicrobial compound triclosan, present in many soaps and toothpastes. She was surprised to learn that it required only a low concentration of triclosan (0.5 ppm) to cause developmental defects.
She’d been familiar with the concept of DNA since middle school, but her fellow science fair finalists were delving beyond their observations and into the letters of the genetic code. This gave her a new impetus: to understand how triclosan worked at the level of the genome and epigenome to engender the physical deformities she observed under the microscope. She just needed the proper tools, so she made some calls.
Environmental geneticist and water flea aficionado John Colbourne took an interest, and invited her to his lab at University of Birmingham in the U.K. the following summer so she could learn basic lab techniques. Although her friends and classmates didn’t quite get why she needed to travel to an entirely different country to study an organism they’d never heard of, as she puts it, she had burning scientific questions that needed answers.
“That was the experience that really turned me on to genomics,” says Sappington, now a senior and 6-7 (Computer Science and Molecular Biology) major. “I was finally getting the tools to dig through large amounts of data, using code to find patterns and meaning. I wanted to keep asking ‘why?’ and ‘how?’ all the way down to the molecular level.”
The summer before her freshman year of college, Sappington asked these questions in humans for the time as an intern at the National Human Genome Research Institute (NHGRI). There, she helped create a computational pipeline to identify the genomic changes associated with heightened risk of cardiovascular disease.
She enrolled at MIT the following fall, because she wanted to be around people from every scientific subfield imaginable. When she arrived, the joint major in computer science and biology was still relatively new.
“While a few of the required classes did meld the two, many of them offered training in each separately,” she says. “That approach really appealed to me because I was hoping to develop both skill sets independently. I wanted to learn code and write algorithms that could be applied to any field, and I also loved understanding the biological mechanisms behind different diseases and viruses.”
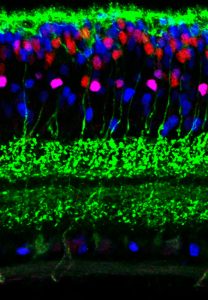
Despite their obvious differences, Sappington found the two areas to be more similar than she had initially anticipated. In her Introduction to Algorithms class, she leveraged an arsenal of algorithms with certain outputs, conditions, and run times to decode her problem sets. In Organic Chemistry, she deployed a list of foundational reactions to solve synthesis questions on her exams. “In each case, you have to combine your understanding of these fundamental rules and come up with a creative solution to decipher an unknown,” she says.
Before she’d even officially declared her major, Sappington was already running experiments in Sangeeta Bhatia’s lab. There, at the Koch Institute, she studied the effects of HPV infection on gene expression in liver cells. Sappington’s main role was data analysis, striving to determine which genes were amplified in response to disease.
One year later, Sappington moved to Aviv Regev’s lab at the Broad Institute. There, she learned computational techniques for decoding protein interaction networks. After a year, she began working on an international project called the Human Cell Atlas as a member of the Regev and the Sanes lab collaboration.
“The overarching mission is to create a reference map of all human cells,” Sappington explains. “We want to add a layer of functional understanding on top of what we know about the genome, to understand how different cell types differ and how they interact to impact disease. This kind of endeavor has never been undertaken on such a large scale before, so it’s incredibly exciting.”
Even within a single cell type — say, retinal cells — there are about six main cell categories, each of which splinter into as many as 40 subtypes with distinct molecular profiles and roles.
Beyond the biological challenges that go along with trying to distinguish all these cell types, there are numerous computational hurdles as well. Sappington enjoys these the most — grappling with how best to analyze the gene expression of a single cell separated from its tissue of origin.
“Since you’re only working with single cells rather than entire groups of cells from a tissue, the data that you get are much more sparse,” she says. “You have to sequence a lot of individual cells and build up lots of statistical power before you can be confident that a given cell is expressing specific genes. Coming up with models to determine what constitutes a cell type — and map cell types between time points or between species — are broad problems in computer science that we’re now applying to this very specific type of data.”
Although she’s been at the Broad since her sophomore year, Sappington has supplemented her MIT research experiences with summer studies elsewhere: another stint at the NHGRI and an Amgen Scholars fellowship in Japan. She’s especially excited because her first co-authored paper will soon be published. As she puts it, she’s finally found her ideal balance of “innovative computer science and innovative biology.”

But Sappington’s time at MIT has been defined by more than just lab work. She is the co-president of the Biology Undergraduate Student Association, which serves as a liaison between the Department of Biology and the wider community. She’s also a member of MedLinks, a volunteer at the Massachusetts General Hospital Department of Radiology, former managing director of TechX, and a performer for several campus dance troupes. In 2018, Sappington earned the prestigious Barry Goldwater Scholarship Award, alongside fellow 6-7 major Meena Chakraborty.
She was recently awarded the Marshall Scholarship, which will fund her master’s degrees in machine learning at University College London and oncology at the University of Cambridge beginning in the fall of 2019. After two years, she plans to start her MD-PhD. That way, she can become a practicing physician without having to give up her computer science research.
Her advice to prospective students: “When you get to MIT, just explore. Try different academic disciplines, different extracurriculars, and talk to as many people as you can. The campus is full of passionate individuals in every field imaginable, whether that’s computer science or political science.”