Category: Uncategorized

Six faculty members are granted tenure in four departments.
Bendta Schroeder | School of Science
June 4, 2018
The School of Science has announced that six members of its faculty have been granted tenure by MIT.
This year’s newly tenured associate professors are:
Daniel Cziczo studies the interrelationship of atmospheric aerosol particles and cloud formation and its impact on the Earth’s climate system. Airborne particles can impact climate directly by absorbing or scattering solar and terrestrial radiation and indirectly by acting as the seeds on which cloud droplets and ice crystals form. Cziczo’s experiments include using small cloud chambers in the laboratory to mimic atmospheric conditions that lead to cloud formation and observing clouds in situ from remote mountaintop sites or through the use of research aircraft.
Cziczo earned a BS in aerospace engineering from the University of Illinois at Urbana-Champaign in 1992, and afterwards spent two years at the NASA Jet Propulsion Laboratory performing spacecraft navigation. Cziczo earned a PhD in geophysical sciences in 1999 from the University of Chicago under the direction of John Abbatt. Following research appointments at the Swiss Federal Institute of Technology and then the Pacific Northwest National Laboratory, where he directed the Atmospheric Measurement Laboratory, Cziczo joined the MIT faculty in the Department of Earth, Atmospheric and Planetary Sciences in 2011.
Matthew Evans focuses on gravitational wave detector instrument science, aiming to improve the sensitivity of existing detectors and designing future detectors. In addition to his work on the Advanced the Laser Interferometer Gravitational-Wave Observatory (LIGO) detectors, Evans explores the physical processes that set fundamental limits on the sensitivity of future gravitational wave detectors. Of particular interest are the quantum and thermal limitations which have the strongest impact on ground-based detectors like LIGO and also play a role in the related fields of ultra-stable frequency references and macroscopic quantum measurement.
Evans received a BS in physics from Harvey Mudd College in 1996 and a PhD from Caltech in 2002. After postdoctoral work on LIGO at Caltech, Evans moved to the European Gravitational Observatory to work on the Virgo project. In 2007, he took a research scientist position at MIT working on the Advanced LIGO project, where he helped design and build its interferometer. He joined the MIT faculty in the Department of Physics in 2013.
Anna Frebel studies the chemical and physical conditions of the early universe, and how the oldest, still-surviving stars can be used to obtain constraints on the nature of the very first stars and early supernova explosions, and associated stellar element nucleosynthesis. She is best known for her discoveries and subsequent spectroscopic analyses of 13 billion-year-old stars in the Milky Way and ancient faint stars in the least luminous dwarf galaxies, to uncover unique information about the physical and chemical conditions of the early Universe. With this work, she has been able to obtain a more comprehensive view of the formation of our Milky Way Galaxy with its extended stellar halo because the formation history of each galaxy is imprinted in the chemical signatures of its stars. To extract this information, Frebel is also involved in a large supercomputing project that simulates the formation and evolution of large galaxies like the Milky Way.
Frebel received her PhD from the Australian National University in 2007. After a W. J. McDonald Postdoctoral Fellowship at the University of Texas at Austin, she completed a Clay Postdoctoral Fellowship at the Harvard-Smithsonian Center for Astrophysics in 2009. Frebel joined the MIT faculty in the Department of Physics in 2012.
Aram Harrow works to understand the capabilities of the quantum computers and quantum communication devices and in the process creates connections to other areas of theoretical physics, mathematics, and computer science. As a graduate student, Harrow developed the idea of “coherent classical communication,” which along with his work on the resource inequality method, has greatly simplified the understanding of quantum information theory. Harrow has also produced foundational work on the role of representation theory in quantum algorithms and quantum information theory. In 2008, Harrow, Hassidim, and Lloyd developed a quantum algorithm for solving linear systems of equations that provides a rare example of an exponential quantum speedup for a practical problem. Recently Harrow has been investigating properties of entanglement, such as approximate “superselection” and “monogamy” principles with the goal of better understanding not only entanglement and its uses, but also the related areas of quantum communication, many-body physics, and convex optimization.
Harrow received his undergraduate degree in 2001 and his PhD in 2005 from MIT. After his PhD, he spent five years as a lecturer at the University of Bristol and then two years as a research assistant professor at the University of Washington. Harrow returned to MIT to join the faculty in the Department of Physics in 2013.
Adam Martin studies how cells and tissues change shape during embryonic development, giving rise to organs with distinct shapes and structure. He has developed a system to visualize and quantify the movement of molecules, cells, and tissues during tissue folding in the fruit fly early embryo, where cells and motor proteins within these cells can be readily imaged by confocal microscopy on the time scale of seconds. Tissue folding in the fruit fly involves conserved genes that also function to form the mammalian neural tube, which gives rise to the mammalian brain and spinal cord. Martin combines live imaging with genetic, cell biological, computational, and biophysical approaches to dissect the molecular and cellular mechanisms that sculpt tissues. In addition, the lab examines how tissues grow and are remodeled during development, investigating processes such as cell division and the epithelial-mesenchymal transition.
After Martin received a BS in biology from Cornell University in 2000, he completed his PhD in molecular and cell biology under the direction of David Drubin and Matthew Welch at the University of California at Berkeley in 2006. After a postdoctoral fellowship at Princeton University in the laboratory of Eric Weischaus, Martin joined the MIT faculty in the Department of Biology in 2011.
Kay Tye dissects the synaptic and cellular mechanisms in emotion and reward processing with the goal of understanding how they underpin addiction-related behaviors and frequently co-morbid disease states such as attention-deficit disorder, anxiety, and depression. Using an integrative approach including optogenetics, pharmacology, and both in vivo and ex vivo electrophysiology, she explores such problems as how neural circuits differently encode positive and negative cues from the environment; if and how perturbations in neural circuits mediating reward processing, fear, motivation, memory, and inhibitory control underlie the co-morbidity of substance abuse, attention-deficit disorder, anxiety, and depression; and how emotional states such as increased anxiety might increase the propensity for substance abuse by facilitating long-term changes associated with reward-related learning.
Tye received her BS in brain and cognitive sciences from MIT in 2003 and earned her PhD in 2008 at the University of California at San Francisco under the direction of Patricia Janak. After she completed her postdoctoral training with Karl Deisseroth at Stanford University in 2011, she returned to the MIT Department of Brain and Cognitive Sciences as a faculty member in 2012.

Chris Kaiser | School of Science
May 31, 2018
Alex Rich had a long and fertile career at MIT working on the relationship between the molecular structure and the function of biological information molecules DNA and RNA. Rich is perhaps best known for the elucidation of the three-dimensional structure of a transfer RNA molecule, and for the discovery of an alternative form of DNA that exists in certain biological contexts, known as Z-DNA.
Less well-recognized is Rich’s contribution to the discovery of nucleic acid hybridization. Hybridization is the process by which single-stranded RNA or DNA molecules can find each other in solution by the exact matching of complementary base sequences. The rate of hybridization is limited only by the rate of diffusion of molecules in solution. Because of its remarkable speed and specificity, hybridization remains today as one of two fundamental methods for reading out the identity of RNA or DNA molecules in different contexts — the direct determination of the base sequence, with the other being carrying out the matching by computer.
Rich grew up in a working-class neighborhood of Springfield, Massachusetts. In high school, he helped support his family by working in the U.S. Armory machining grooves in rifle barrels. As a young man, Rich was smart, resourceful, and ambitious and he received a fellowship to Harvard College and later attended Harvard Medical School. At Harvard, Rich had the opportunity to work with Professor of Biological Chemistry John Edsall, who sparked an interest the physical chemistry of biological macromolecules that eventually led him away from medicine to postgraduate research with the visionary chemist and ebullient polymath Linus Pauling at Caltech.
Pauling discovered the alpha helix as a basic element of protein structure and by doing this invented the method of model building as a way of predicting the large-scale structural features of complex macromolecules from the chemical bonding structures of their constituent parts. In Pauling, Rich found a powerful role model who showed by example how far you could travel by grasping a good idea or deep insight.
When Rich joined the lab, Pauling was working on a structure for DNA and then was, to put it bluntly, scooped by James Watson and Francis Crick. Watson and Crick’s structure for DNA, based on astute model building and the X-ray diffraction data of Rosalind Franklin, was published in 1953. The key feature of their structure was the exact pairing of the bases between two strands of DNA that twist around each other in a double helix. The base-pairing rules — adenine pairs with thymine and guanine pairs with cytosine — are imposed by the geometric constraints on the paired bases as they are held together by hydrogen bonds in the central core of the helix. The double helix can accommodate a string of bases of any sequence and thus carry genetic information encoded in linear sequences of four characters. Moreover, the exact base-pairing between strands means that each strand carries the same information as the other, but in complementary form, and immediately suggested how the genetic information can be duplicated for cell division.
Big Bang and the coding problem
The emerging picture that the base sequence of DNA carried instructions to synthesize linear strings of protein out of a set of 20 amino acids led to a deeper puzzle: how could information encoded in the sequence of one kind of macromolecule be translated into the sequence of an entirely different kind of molecule? Although its direct involvement had not yet been shown, RNA was strongly suspected to have a central role in this process. One of the clues to the involvement of RNA was that RNA was most abundant in animal or plant tissues undergoing rapid growth and therefore extensive new protein synthesis. DNA and RNA are similar molecules and both are polymers of four nucleotide bases, but they differ in that DNA contains a hydrogen atom at the 2’ position on the ribose ring, whereas RNA contains a hydroxyl group at this position. The absence of a hydroxyl group at this position makes DNA more chemically stable and therefore more suitable to carry the permanent copy of genetic information. Also, DNA carries the base thymine instead of the chemically similar base uracil in RNA.
The brilliant theoretical cosmological physicist George Gamow, who was an early proponent of the Big Bang theory, saw that there was something worthy of interest in RNA and what soon became known as the “coding problem.” Gamow helped to focus thinking about this problem by posing the question of how a code written in four bases could be translated into 20 different amino acids. The introduction of the principles of information theory, first proposed in Claude Shannon’s 1948 paper “A Mathematical Theory of Communication,” immediately suggested that at least three bases would be required to carry enough information to specify 20 different amino acids. Gamow organized interested scientists in a group that called themselves the RNA Tie Club — so named for members’ necktie clips that bore the abbreviation of an amino acid. Rich was a member, as were Watson and Crick; and these members would share with one another ideas and insights before publication. Since each member of the club was assigned a different amino acid, membership never exceeded 20.

Rich was captivated by the connection, as so beautifully illustrated by the DNA model, between chemical structure and biological function and he was determined to make his mark in this new field as a structural biologist. He wondered if RNA could form a double helical base-paired structure and what role might this structure have in translating a DNA code into amino acids. With the help of Watson, who was at Caltech at that time, Rich set about analyzing different kinds of natural RNA samples, but none showed the characteristic diffraction pattern in X-ray analysis that Franklin had seen for double helical DNA.
Rich took a job at the NIH. There and on a sabbatical to Cambridge, England, he had success with various structural and modelling studies, including a structure for collagen, but he kept coming back to the question of whether a double-stranded RNA helix could form. One of the most precise analytical tools for nucleic acids such as RNA available at the time was to measure the base composition — that is, the relative proportion of guanine, cytosine, adenine and uracil. For a fully double-stranded molecule, base pairing rules would dictate that the amount of guanine should equal cytosine and the amount of adenine should equal that of uracil. The natural RNA samples that Rich was studying had very different base compositions, but did not follow the rules expected for a double-stranded structure. Eventually, Rich decided to force the issue by synthesizing his own RNA molecule that could form a fully base–paired double strand.
Rich and his colleague David Davies used the enzyme polynucleotide phosphorylase, which could polymerize into chains whatever activated nucleotide precursors were provided, to prepare two RNA chains designed to be able to base pair with each other. In one reaction, they prepared a long strand of RNA with only adinines (oligo-A) and in a separate reaction a long strand of RNA made up entirely of uracil (oligo-U). Hoping to see some amount of base pairing, Rich mixed the two preparations together and was amazed to see the entire contents become converted into RNA with the properties of double-stranded molecules. X-ray analysis confirmed that the two chains had had coiled around each other into a double helix. This experiment showed that an RNA-based double helix was possible, but the speed with which the double-stranded molecules formed was entirely unexpected. Based on physical chemistry of polymers, Rich had expected that some additional factors, such as enzymes, would be needed to neatly coil long disordered chains around each other. The effect of seeing this dramatic reorganization of molecules happen so efficiently might be the equivalent of seeing two tangled fishing lines that were thrown together spontaneously wrap themselves into a neat braid.
Such spontaneous base pairing between different nucleic acid chains is known as hybridization and is the fundamental underlying chemical process by which the information in DNA is translated into protein. Rich went on to show that hybridization between a DNA strand (oligo-dT) and an RNA strand (oligo-A) could occur to form a hybrid of RNA based paired with DNA. This molecule provided a structural basis for copying information from the gene sequence in DNA into a complementary single-stranded messenger RNA molecule. Moreover, base pairing between triplet codons on the messenger RNA and the anticodon loop of a transfer RNA carrying a specific amino acid is the basis by which the nucleotide code is translated into amino acid sequence.
Hybridization has become an enduring method in molecular biology and biotechnology research. Shortly after Rich carried out his RNA hybridization reaction, it was shown that the two strands of DNA could be melted apart at high temperature and then could come back together in a sequence specific manner if held at a somewhat lower annealing temperature. Before methods for direct sequencing of DNA became available, hybridization was the only method by which specific DNA or RNA sequences could be identified in a complex mixture.
Hybridization has become an enduring method in molecular biology and biotechnology research. Shortly after Rich carried out his RNA hybridization reaction, it was shown that the two strands of DNA could be melted apart at high temperature and then could come back together in a sequence-specific manner if held at a somewhat lower annealing temperature. Before methods for the direct sequencing of DNA became available, hybridization was the only method by which specific DNA or RNA sequences could be identified in a complex mixture.
Hybridization was crucial for the discovery of splicing of messenger RNA made by MIT Institute Professor Phil Sharp and was the basis for Professor Susumu Tonegawa’s demonstration of DNA rearrangements that underlie the formation of functional genes for antibodies. Even now, with extremely powerful methods for DNA sequencing, hybridization is still often used to examine the structure of chromosomes and to conduct comprehensive studies of gene expression based on microarrays. Finally, sequence-specific hybridization is at the heart of natural processes that have been harnessed for RNA interference of gene expression and CRISPR-based genome editing.
Rich himself wrote and spoke extensively about the early years of molecular biology in ways that reveal two important characteristics as a scientist. The first is that his deep admiration for mentors such as Pauling and colleagues such as Crick and Watson was the basis of an intellectual network that sustained Rich his entire career. By his account, a new discovery in the lab was invariably followed by a letter or a phone call to those that he admired to get their reactions. All biologists, no matter how great, struggle with the problem that it is difficult — if not impossible — when setting out on a new problem to predict whether it will reveal insights fundamental to all living things or merely lead to odd details produced as a byproduct of the tinkering of evolution. Rich was adept at vetting new ideas through his constellation of brilliant friends to guide him toward the fundamental.
The second, related characteristic is Rich’s gift for seeing how new concepts may play out in time — well into the future. In the spirit of the RNA Tie Club, Rich freely shared his imaginative speculation about where he saw the field going, adding these forward-thinking ideas to his review articles and sprinkling their seeds in the discussion sections of his research papers. Among his more prescient ideas was the prediction that hybridization to messenger RNA of a complementary regulatory RNA could play a part in gene regulation; this prediction anticipated the discovery of microRNA-based regulation by about 40 years. He also hypothesized in the early 1960s that early life forms could have a genetic system without DNA that was made up of only RNA. This may be the first articulation of the now widely accepted idea of an RNA world. As I knew Rich in his later years, he remained engaged in and stimulated by new ideas. It was not difficult when chatting with him in his office or going on a walk-and-talk with him to feel connected to and stimulated by the sweep of brilliant ideas that have propelled molecular biology along from the very beginning.
May 31, 2018

Chris Kaiser | School of Science
May 22, 2018
This story was originally published on the MIT School of Science.
The rise of the information age in the second half of the 20th century was spurred on by two related but distinct scientific and technological revolutions. The first, of course, was the digital revolution, which emerged with the development of the mathematics necessary for computation and data storage based entirely on a binary code. The second revolution came about from the discovery that information encoded in the molecular sequence of DNA carries the instructions for the working parts of a cell and thus is the blueprint of life. The field of molecular biology emerged as the study of how genetic information is transmitted from one generation to another and is read out to form functional cellular components and regulatory circuits.
The foundational science of molecular biology has led to methods for reading and writing biological information and to alter genomes by design. The capability to reprogram living organisms to do useful things forms the basis of the biotechnology industry.
No single institution has had a greater impact in accelerating the revolution in molecular biology and biotechnology than MIT. The origins of this revolution is woven deeply into the history of the Department of Biology.
MIT’s revolutionary foundation
In the late 1950s, MIT’s administration began a deliberate and concerted effort to recruit molecular biologists even before this nascent research area was recognized as a distinct field that would transform all of biology. The decision was made to hire faculty who were interested in studying biology by uncovering relationships between molecular structure and function and understanding the biochemical basis of genetic information and the transmission of genetic traits.

At the University of Wisconsin, Gobind Khorana celebrates his 1968 Nobel Prize in Physiology or Medicine awarded for his contributions to elucidation of the genetic code. Even at this celebration, he was already looking forward to the next experiments. Here, he explains the strategy for enzymatic gene synthesis using diagrams of hybridizing strands. Photo: Tom RajBhandary.
One such seminal hire was Alex Rich, the William Thompson Sedgwick Professor of Biophysics, who came to MIT in 1958. Rich contributed to the discovery of how single strands of DNA and RNA molecules can find and match complementary sequences. This process, called nucleic acid hybridization, remains one of the fundamental methods for reading out the identity of nucleic acid molecules. In addition to foundational research into hybridization, Rich also elucidated the three-dimensional structure of the transfer RNA molecule that functions in reading the genetic code.
A second enormously influential hire was Salvador Luria who moved from the University of Illinois to MIT in 1959. Luria was a leader in the study of bacteriophages — viruses that infect bacterial cells. Much in the same way that early quantum physicists used the hydrogen atom to establish a theory for quantum structure of atoms, the first molecular geneticists used the bacteriophage as a simple genetic system to reveal the rules for fundamental genetic processes such as replication, recombination, and mutation.
By the 1960s, the understanding of fundamental genetic mechanisms developed by Luria and others had merged with the work of structural biologists such as Rich to give the outline of how genetic information was stored, copied, and read.
The reading of genetic information takes place in two steps. In the first step, known as transcription, genetic information encoded in DNA is used as a template to make a copy in the form of a single-stranded messenger RNA. In the second step, the information contained within the messenger RNA is translated into a protein sequence at the site of protein synthesis — the ribosome. Transfer RNA molecules serve as the key adaptor molecules that allow translation of messenger RNA sequences into the amino acid sequences of proteins. Each transfer RNA carries a triplet of nucleotides that pairs with and thus “reads” a specific three-nucleotide sequence along the messenger RNA. At its other end, the transfer RNA carries a particular amino acid that is added in its place in the sequence of the elongating protein chain.
Khorana cracks the code
Before Har Gobind Khorana arrived in Cambridge, Massachusetts in 1970, he worked with the great nucleotide chemist, Alexander Todd at the University of Cambridge in the United Kingdom. Khorana was in the lab at the time that chemists were working out structure of the nucleotide building blocks of DNA and RNA. When Khorana started his own lab, first at University of British Columbia and then at University of Wisconsin, his work was devoted to using synthetic chemistry to make biologically important molecules and ever more complicated polynucleotide structures.
Khorana made one of the most consequential advances in molecular biology by using a hybrid approach that employed organic chemistry to synthesize short sequence of a few nucleotides followed by the use of a copying enzyme to generate long DNA molecules with many repeating copies of the short sequence. Khorana’s molecules with a repeating sequence were the keys to cracking the genetic code. A few years earlier, the complex process of translation was reconstituted in the test tube and was dependent on messenger RNA added from the outside. By using synthetic messenger RNAs to instruct the synthesis of proteins by the ribosome, Khorana’s group was able to work out rules for how specific sequences of three nucleotides in RNA are translated into the 20 possible amino acids. We now know that all forms of life use the same genetic code to read the information written in DNA. For his contributions to understanding the code, Khorana shared the 1968 Nobel Prize for Physiology or Medicine.
Synthesizing genes
As work on the code was nearing completion, Khorana began thinking about how to synthesize long polynucleotide molecules of even greater complexity. He had his eye on what could be considered a moonshot challenge in nucleic acid synthesis: to synthesize a functional gene.
Before an artificial gene could be synthesized, it was necessary, of course, to know the DNA sequence of the desired gene. In the mid-1960s, the ability to directly determine the DNA sequence of a protein-coding gene was still about a decade away; however, the DNA sequence of an RNA-coding gene could be deduced directly from the RNA sequence. The first complete sequence of a natural gene-encoded RNA molecule — the transfer RNA for the amino acid alanine — was determined by Robert Holley in 1965. In that year, Khorana began to organize his lab to synthesize the double-stranded DNA that would code for alanine transfer RNA. Although Khorana knew that this monumental task would require a combined and concerted effort of perhaps a decade of work, he expressed utter clarity and confidence in the purpose and significance of this endeavor.
In a review letter for the Biochemical Journal in 1968, he wrote: We would like to know, for example, what the initiation and termination signals for RNA polymerase are, what kind of sequences are recognized by repressors, by host modification and host restrictive enzymes, and by enzymes involved in genetic recombination, and so on. For these studies, ultimately what is required is the ability to synthesize long chains of DNA with specific non-repeating sequences. With this should come the ability to ‘manipulate’ DNA for different types of studies.
This description pretty well summarizes the work of a major segment of molecular biology for the next 50 years.
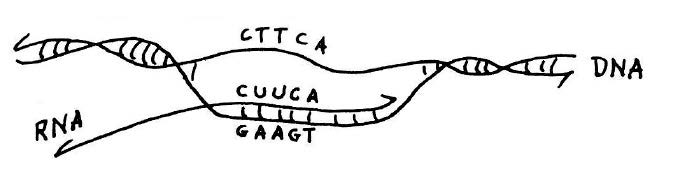
Copying of genetic information in DNA into RNA.Transcription is catalyzed by the enzyme RNA polymerase (not shown). This diagram shows that if the sequence of the RNA transcript is known, as was the case for alanine transfer RNA, the DNA sequence of the corresponding gene for the transfer RNA can be deduced from the rules of base pairing. This and figure below from he published lecture notes of Professor Salvador Luria who taught general biology (7.01) at MIT for many years. Credit: MIT Press, 1975, “36 Lectures in Biology.”
In theory, the DNA for alanine transfer RNA could be formed by synthesizing each complementary strand separately and then using hybridization to form a complete double-stranded helix. This approach would require synthesis of DNA strands that were 77 nucleotides long; however, at the time the upper limit for synthesis, even in Khorana’s laboratory, was about 20. The plan as originally conceived was to take advantage of the ability of DNA polymerase to synthesize DNA from a template. The idea was to synthesize oligo-nucleotides that partly overlapped and then to use DNA polymerase to complete a fully double-stranded DNA molecule. Khorana’s team started the synthesis of the gene for alanine transfer RNA in this way and showed that basic strategy of using chemical synthesis followed by synthesis by polymerase would work. But when the DNA ligase enzyme was discovered, it became more practical to chemically synthesize many short overlapping segments and stitch them together with ligase. In this manner, the synthesis of alanine transfer RNA gene was completed in 1970.
The first synthetic gene was in itself a monumental landmark in the progression of molecular biology; but like any successful moonshot, the technological innovations developed along the way may have had the furthest-reaching impact.
Knock-on effects
Marvin Caruthers joined Khorana part of the team synthesizing the alanine transfer RNA in 1966 and then came with him to MIT. Caruthers then went to the University of Colorado at Boulder, where he began his own research program developing methods for reliable automated synthesis of short DNA molecules, or oligonucleotides. He decided to carry out nucleotide synthesis on a solid support, which would greatly simplify and speed up the separation of the growing oligo-nucleotide chain away from precursor molecules as the process stepped through the reaction cycle for the addition of each base in the sequence.
Khorana had the vision and leadership to convince a team to follow him to an unknown place, and he had the supreme confidence that he would know what to do once he got there.
A second key innovation was Caruther’s development of nucleotide precursors that could be stored for long periods and then readily activated immediately before use. The so called “phosphoramidite method” for DNA synthesis was automated and its use enables scientists who are not expert organic chemists to synthesize their own oligonucleotides. The ready availability of oligonucleotide primers has driven the expansion of methods for reading DNA by sequencing and the copying and modification of DNA sequences at will. These technologies are analogous to the fundamental output and input devices of a digital computer but for the manipulation of biological information encoded in DNA.
The development of the by polymerase chain reaction (PCR) is another key technological advance that stemmed from Khorana’s work. PCR employs the same basic elements proposed by Khorana for the synthesis of the alanine transfer RNA gene; hybridization of synthetic oligonucleotides to a target DNA followed by synthesis with DNA polymerase to produce double-stranded DNA of defined sequence. The key innovation as proposed by Kary Mullis when he came up with the idea for PCR was to use the same synthetic oligonucleotides to conduct many cycles of hybridization and synthesis. Because of the doubling that results from each round of replication, 20 cycles would give a million-fold amplification allowing a specific sequence to be produced from an extremely complex mixture such as a whole genome.
Twelve years before the invention of PCR, Khorana’s group showed that oligonucleotides defining the ends of the completed transfer RNA gene segment could be used to carry out rounds of hybridization and DNA synthesis with polymerase to make more of the desired DNA product without any additional labor in chemical synthesis of DNA. This raises the question of whether Khorana, who was a visionary, foresaw the possible application of his method for the amplification of sequences from whole genomes. It is worth pointing out that at the time Khorana’s group was contemplating enzymatic amplification, their synthetic gene was one of the only DNA sequences that was known and therefore a basic ingredient of the PCR method — knowledge of enough of an interesting target sequence to design the oligonucleotide primers for its amplification — was not available to them. Years later, when PCR patents were under litigation, the question of prior art arose; but Khorana refrained from comment, having moved on to the study of the light-sensing protein rhodopsin.
Visions for the next revolution
At a memorial service for Khorana held at MIT in 2012, many stories were told about his intellectual independence and visionary leadership in basic research that had far-reaching implications.
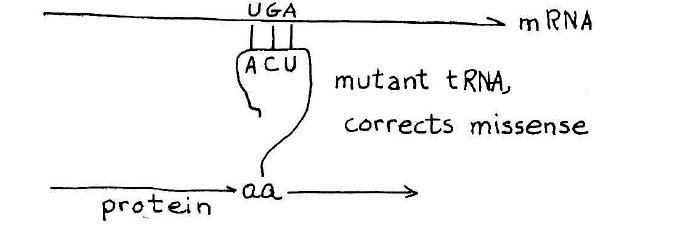
How a suppressor transfer RNA works. A stop codon introduced in the middle of a gene will cause premature termination of the protein chain. A suppressor transfer RNA has been altered so that it can read past a stop mutation suppress its effect. This provides a definitive genetic demonstration for functionality of a suppressor transfer RNA gene. Credit: MIT Press, 1975, “36 Lectures in Biology.”
As the synthesis of alanine transfer RNA gene was well underway, Khorana initiated a project reaching for an even bigger prize — a synthetic gene that could be shown to carry out its biological function in the context of a living cell. The candidate, known as a suppressor transfer RNA, was a recently sequenced transfer RNA that had the ability to read past a stop mutation introduced in the middle of a gene, thereby suppressing the effect of the mutation and allowing ribosomes to read the RNA and produce the protein. The idea that Khorana laid out for the team was to synthesize the suppressor transfer RNA and then introduce the synthetic gene into a suitable bacterial host designed to test its ability to suppress a stop mutation.
At that time, now standard methods for gene cloning and expression did not exist. As the planning moved forward, the team synthesizing the suppressor transfer RNA began to envision more and more elaborate schemes to get a functional suppressor transfer RNA gene into cells. As Caruthers related the story, Khorana listened quietly to the brainstorming for a bit and then said, “Let’s first synthesize the gene. By that time, we will know how to express it.” Khorana was right; and by the time the synthetic suppressor gene was complete, methods were available for introducing the gene into cells.
Like the great explorers Frances Drake and Ernest Shackleton who were my heroes growing up, Khorana had the vision and leadership to convince a team to follow him to an unknown place, and he had the supreme confidence that he would know what to do once he got there.
Transformational scientific and technological revolutions, like those initiated by Khorana, Luria, and Rich, are of keen interest because they help us understand the sparks of genius and originality that we should be looking for when we hire new faculty and illustrate the kinds of research projects in our institutions and companies that might lead to fundamental advances in preparation for the next scientific revolution.
Chris Kaiser is the Amgen Inc. Professor of Biology and the former head of the MIT Department of Biology.

Biologist honored for his work developing yeast as a model organism for genetic studies.
Anne Trafton | MIT News Office
May 16, 2018
Gerald Fink, an MIT biologist and former director of the Whitehead Institute, has been named the recipient of the 2018-2019 James R. Killian Jr. Faculty Achievement Award.
Fink, the Margaret and Herman Sokol Professor in Biomedical Research and American Cancer Society Professor of Genetics, was honored for his work in the development of baker’s yeast, Saccharomyces cerevisiae. Fink’s work transformed yeast into the leading model for studying the genetics of eukaryotes, organisms whose cells contain nuclei.
“Professor Fink is among the very few scientists who can be singularly credited with fundamentally changing the way we approach biological problems. He has made numerous seminal contributions to understanding the fundamentals of all nucleated life on the planet, significantly advancing our knowledge of many cellular processes critical to life systems and human diseases,” according to the award citation, which was read at the May 16 faculty meeting by Michael Strano, the chair of the Killian Award selection committee and the Carbon P. Dubbs Professor of Chemical Engineering at MIT.
Established in 1971 to honor MIT’s 10th president, James Killian, the Killian Award recognizes extraordinary professional achievements by an MIT faculty member. “From understanding how cells are formed and function, to understanding cancer and developing insights into aging, his research has proved critical to modern day science,” the award committee wrote of Fink.
Fink, who was inspired to go into science partly by the Soviet Union’s launch of the Sputnik satellite in 1957, began studying yeast while working toward his PhD at Yale University in the 1960s.
“I studied yeast as a graduate student, when it was an extremely unpopular organism,” Fink recalls. “In fact, I was cautioned by my thesis advisor not to tackle it because it was an intractable system.”
Despite that warning, Fink dove into studies of yeast metabolism — in particular, the mechanism that yeast uses to regulate amino acid biosynthesis. At the time, yeast engineering was impeded because there was no way to insert a gene into yeast cells. Then, in 1976, Fink developed a way to insert any DNA into yeast cells, thus allowing researchers to study gene functions in eukaryotic cells in a way that was previously impossible.
“That technology dramatically changed everything, because it made it possible to insert a gene from any organism into yeast,” Fink says.
Fink’s advance allowed scientists to manipulate the yeast genome at will, turning the organism into a cell factory. This technology enabled the current large-scale production of vaccines, drugs (including insulin), and biofuels in yeast.
Fink, who joined the MIT faculty in 1982, currently studies the fungus Candida albicans — which can cause thrush, yeast infections, and severe blood infections — in hopes of developing new antifungal drugs. His lab recently discovered how this human pathogen switches back and forth from its usual yeast form to an invasive filamentous form.
Fink taught genetics to MIT undergraduates and graduate students for many years, and as director of the Whitehead Institute from 1990 to 2001 oversaw the Whitehead’s contribution to the Human Genome Project.
“The Human Genome Project would not have happened here at MIT if it had not been for the unique structure of the Whitehead Institute, which was able to move quickly,” Fink says. “We committed resources and space from the Whitehead to propel the project forward.”
In 2003, the Whitehead/MIT Center for Genome Research became the cornerstone of the newly launched Broad Institute. “MIT’s premier place in the world of biological research is due in no small part to Professor Fink’s selfless, tireless, and generally unheralded work in creating and nurturing these institutions,” reads the award citation.
In 2003, Fink chaired the National Academy of Sciences Committee on Research Standards and Practices to Prevent the Destructive Application of Biotechnology, which provided the nation with guidance on how to deal with the threat of bioterrorism without jeopardizing scientific progress.
Fink has received many other honors, including the National Academy of Sciences Award in Molecular Biology, the George W. Beadle Award from the Genetics Society of America, and the Gruber International Prize in Genetics. He has served as president of both the American Association for the Advancement of Science and the Genetics Society of America, and he is an elected member or fellow of the National Academy of Sciences, the American Academy of Arts and Sciences, the Institute of Medicine, and the American Philosophical Society.

Linc Sonenshein and Rich Losick
May 15, 2018
When the two of us, who were classmates and dorm mates at Princeton, came to MIT in 1965, we were joined by two other Princeton classmates, Mike Newlon (also a dorm mate) and Charlie Emerson. As a result, our Princeton class produced four of the 20 students who formed the entering class of 1965 of the MIT Biology Graduate Program. (The class was originally meant to include 21 students, but one of the accepted students, the recent Nobel Prize recipient Michael Rosbash, decided to spend a year at the Pasteur Institute before joining the MIT program.) Initially, we roomed together with Mike in Porter Square with a fourth member of our class, Ray White. As PhD students, we worked in the labs of Phillip Robbins (Rich), Salvador Luria (Linc and Mike), and Maury Fox (Ray); Charlie moved to UCSD to finish his degree. Back then the Luria and Robbins labs were located in Buildings 56 and 16. (Why does MIT use numbers rather than names for their buildings?) The department consisted of semi-independent sub-departments of Biochemistry, Microbiology, and Biophysics. All of us eventually became faculty members at various universities: Rich at Harvard, Linc at Tufts Medical School, Mike at Rutgers, Ray at UMass, Utah, and UCSF, and Charlie at UMass Medical School.
At Princeton, Rich had done thesis research in the lab of Charles Gilvarg, studying the synthesis of lysine oligopeptides in E. coli; Mike and Linc worked in the lab of Donald Helinski on the genetics of colicin synthesis. Our backgrounds in microbiology research served as inducements to continue studying microbes at MIT and throughout our careers. Indeed, Linc’s PhD thesis research with Luria on the bacterium Bacillus subtilis and its ability to produce spores sparked a collaboration with Rich that greatly influenced both their subsequent careers. Yet another lifelong collaboration emerged when Linc married another member of our class, Gail Entner, who worked with Ned Holt and went on to become a professor at Boston University Medical School and Tufts Medical School. Mike Newlon also married a classmate, Carol Shaw, who was also in the Holt lab and has been a professor at the University of Iowa and Rutgers Medical School.
Linc and Rich are proud to have trained many students (six of whom went on to be postdocs at MIT) and multiple postdocs who have continued productive careers in their own labs based on our beloved B. subtilis bacterium. Indeed one such individual went on to become the chairman of the very department for which we have written these recollections.
Memories fade with time, but we have recreated at least a partial list of the entering class of 1965 and their mentors.
Entering Class of 1965: Name (Lab) Academic/Industry Employment
Roberta Berrien (B. Magasanik) MD, VA Health Center
Lynne Brown (V. Ingram) Penn State University
Gail Bruns (V. Ingram) Children’s Hospital, Harvard Medical School
Judith Ebel Tsipis (M. Fox) Brandeis University
Charles Emerson (moved to UCSD) UMass Medical School
Gail Entner Sonenshein (C. Holt) Boston University Medical School, Tufts Medical School
Stephen Fahnestock (A. Rich) Penn State University, DuPont
Costa Georgopoulos (S. Luria) University of Utah, University of Geneva
John Lisman (J. Brown) Brandeis University
Richard Losick (P. Robbins) Harvard University
Susan Neiman Offner (B. Magasanik) Plymouth, Milton, and Lexington High Schools
Michael Newlon (S. Luria) University of Iowa, Rutgers
Steven Raymond (J. Lettvin) MIT, Harvard Medical School, Personal Health Technologies, Inc.
Carol Shaw Newlon (C. Holt) University of Iowa, Rutgers Med School
Abraham L. Sonenshein (S. Luria) Tufts Medical School
Joel Sussman (A. Rich) Weizmann Institute
Walter Vinson (E. Bell)
Raymond White (M. Fox) UMass Med School, University of Utah, UC San Francisco

Faculty director discusses the future of the initiative and Africa’s position as a global priority for the Institute.
Sarah McDonnell | MIT News Office
May 8, 2018
In 2017, MIT released a report entitled “A Global Strategy for MIT,” which offered a framework for the Institute’s ever-growing international activities in education, research, and innovation. The report, written by Richard Lester, associate provost for MIT overseeing international activities, offered recommendations organized around three broad themes: bringing MIT to the world, bringing the world to MIT, and strengthening governance and operations.
Specifically, Lester identified China, Latin America, and Africa as global priorities and regions where the Institute should expand engagement.
Reflecting that increased focus, the MIT-Africa initiative, led by Faculty Director Hazel Sive, a professor in the Department of Biology and member of the Whitehead Institute for Biomedical Research, has launched a new website, africa.mit.edu, to further formalize MIT’s commitment to expanding its already robust presence in Africa. Sive spoke with MIT News about the initiative’s future and Africa’s position as a global priority for MIT.
Q: Can you start by explaining what the MIT-Africa initiative is?
A: MIT-Africa began in 2014 as a mechanism to promote and communicate connections between MIT students, faculty, and staff, and African counterparts in the spheres of research, education, and innovation.
Together with the enthusiastic participation of many faculty, senior staff, and students, I originated the MIT-Africa initiative because a number of us who are either from Africa (I am from South Africa) or interested in the continent were doing important work together with African colleagues. We thought that the strong connections MIT was making in Africa should be understood more broadly, and that tremendous synergies would develop from sharing our work and promoting joint projects.
The initiative provided the first public face of MIT engagement with Africa, comprising a portal to disseminate information, and a means to invite potential collaborators to connect with MIT. We developed community through the MIT-Africa Interest Group; through supporting student groups such as the African Students Association and through a growing network of MIT students who have interned or worked in Africa.
MIT-Africa both consolidates Africa-relevant opportunities and directly promotes new programs. Multiple MIT initiatives and units include an Africa focus: the MIT International Science and Technology Initiatives (MISTI), D-Lab, the Abdul Latif Jameel Poverty Action Lab (J-PAL), the Abdul Latif Jameel World Water and Food Security Lab (J-WAFS), the Abdul Latif Jameel World Education Lab (J-WEL), the Environmental Solutions Initiative (ESI), MITx, the Legatum Center, and others.
The tagline for MIT-Africa is “Collaborating for impact,” and through the pillars of research, education, and innovation, our goal is to develop even more substantial collaborations between the MIT community and in Africa.
Q: What are your thoughts on Africa’s inclusion as a priority in MIT’s recent global strategy report?
A: We are very pleased that MIT has recognized the importance of Africa in the world and as a focus for the Institute.
At the outset of the MIT-Africa initiative, we brought together an Africa Advisory Committee for strategic discussions. Last year, at the request of Richard Lester, we put together a strategic plan for MIT engagement in Africa, and the findings in this document interfaced with his decision to define Africa as a global priority for MIT.
In our plan, we made it clear that MIT priorities overlap with issues of vital importance to Africa — in tackling critical challenges relating to the environment, climate change, energy, population growth, food, health, education, industry, and urbanization. We are confident that this emphasis will facilitate expanded connections between MIT and our African collaborators and supporters.
A useful outcome of formalizing MIT’s priority of Africa engagement is recognition of our already extensive engagement with Africa. MIT has projects in half the countries of Africa! There are hundreds of examples in progress, from water utilization in Mozambique to entrepreneurship in South Africa and education in Nigeria. We are well-represented, and this engagement is growing rapidly.
The new website is both a way to acknowledge the outstanding scholarship and work already progressing on the continent, as well as a call to expand collaborations in a high impact way.
Q: What’s next for MIT-Africa?
A: Our strategic discussions identified key priorities over the next five years. These include: higher visibility of MIT in Africa through “MIT-Africa” branding, coordination in purpose and scope of MIT engagement in Africa, increased student internship and travel opportunities, increased research funding, new collaborations in education, expanded innovation presence, revised Africa-relevant education at MIT, and increased numbers of African trainees at MIT.
We are well on our way to meeting these goals, aided by a team with broad experience. For example, in 2014, we sent two students to Africa through MISTI, and last year we sent 92, so this has been a hugely fast-growing program. The MISTI Global Seed Fund Program newly includes Africa, and units such as J-WAFS, J-WEL, and ESI offer research funding that can be focused on Africa. A key aspect encompasses our alumni who envision a significant and influential African and African diaspora alumni group.
The distinguished MIT-Africa Working Group advises on policy, strategy, and implementation. Many members are leaders of other MIT initiatives, facilitating development of intersecting and productive joint programs with MIT-Africa.
All of this takes effort and collaborators, and we look forward to an expanded set of connections. We extend an invitation to potential collaborators: Come and speak with us. The expertise at MIT is enormous, and our focus on Africa-relevant engagement will have outcomes that advance intellectual, societal, and economic trajectories.
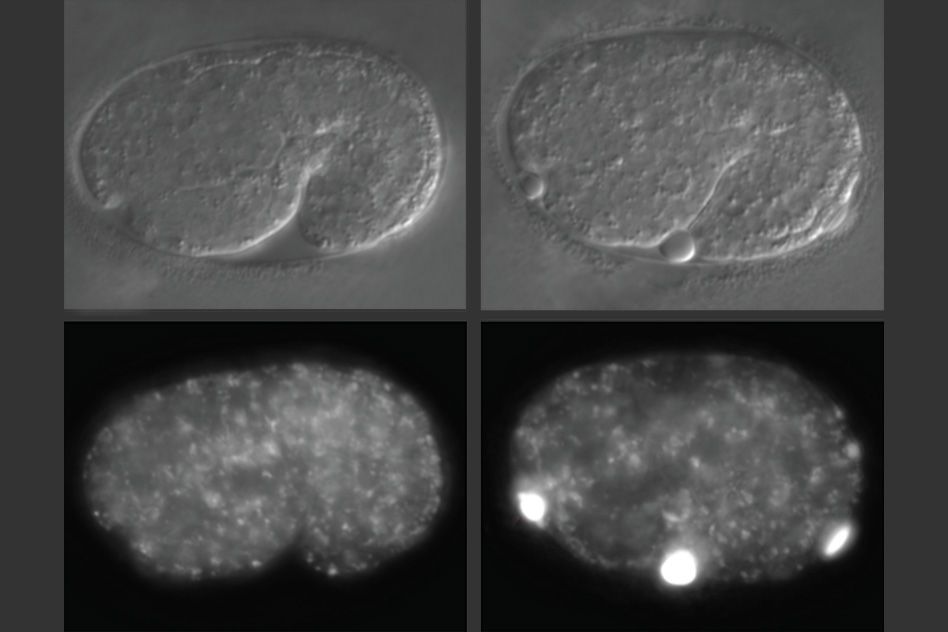
Study in worms reveals gene loss can lead to accumulation of waste products in cells.
Anne Trafton | MIT News Office
May 4, 2018
MIT biologists have discovered a function of a gene that is believed to account for up to 40 percent of all familial cases of amyotrophic lateral sclerosis (ALS). Studies of ALS patients have shown that an abnormally expanded region of DNA in a specific region of this gene can cause the disease.
In a study of the microscopic worm Caenorhabditis elegans, the researchers found that the gene has a key role in helping cells to remove waste products via structures known as lysosomes. When the gene is mutated, these unwanted substances build up inside cells. The researchers believe that if this also happens in neurons of human ALS patients, it could account for some of those patients’ symptoms.
“Our studies indicate what happens when the activities of such a gene are inhibited — defects in lysosomal function. Certain features of ALS are consistent with their being caused by defects in lysosomal function, such as inflammation,” says H. Robert Horvitz, the David H. Koch Professor of Biology at MIT, a member of the McGovern Institute for Brain Research and the Koch Institute for Integrative Cancer Research, and the senior author of the study.
Mutations in this gene, known as C9orf72, have also been linked to another neurodegenerative brain disorder known as frontotemporal dementia (FTD), which is estimated to affect about 60,000 people in the United States.
“ALS and FTD are now thought to be aspects of the same disease, with different presentations. There are genes that when mutated cause only ALS, and others that cause only FTD, but there are a number of other genes in which mutations can cause either ALS or FTD or a mixture of the two,” says Anna Corrionero, an MIT postdoc and the lead author of the paper, which appears in the May 3 issue of the journal Current Biology.
Genetic link
Scientists have identified dozens of genes linked to familial ALS, which occurs when two or more family members suffer from the disease. Doctors believe that genetics may also be a factor in nonfamilial cases of the disease, which are much more common, accounting for 90 percent of cases.
Of all ALS-linked mutations identified so far, the C9orf72 mutation is the most prevalent, and it is also found in about 25 percent of frontotemporal dementia patients. The MIT team set out to study the gene’s function in C. elegans, which has an equivalent gene known as alfa-1.
In studies of worms that lack alfa-1, the researchers discovered that defects became apparent early in embryonic development. C. elegans embryos have a yolk that helps to sustain them before they hatch, and in embryos missing alfa-1, the researchers found “blobs” of yolk floating in the fluid surrounding the embryos.
This led the researchers to discover that the gene mutation was affecting the lysosomal degradation of yolk once it is absorbed into the cells. Lysosomes, which also remove cellular waste products, are cell structures which carry enzymes that can break down many kinds of molecules.
When lysosomes degrade their contents — such as yolk — they are reformed into tubular structures that split, after which they are able to degrade other materials. The MIT team found that in cells with the alfa-1 mutation and impaired lysosomal degradation, lysosomes were unable to reform and could not be used again, disrupting the cell’s waste removal process.
“It seems that lysosomes do not reform as they should, and material accumulates in the cells,” Corrionero says.
For C. elegans embryos, that meant that they could not properly absorb the nutrients found in yolk, which made it harder for them to survive under starvation conditions. The embryos that did survive appeared to be normal, the researchers say.
Neuronal effects
The researchers were able to partially reverse the effects of alfa-1 loss in the C. elegans embryos by expressing the human protein encoded by the c9orf72 gene. “This suggests that the worm and human proteins are performing the same molecular function,” Corrionero says.
If loss of C9orf72 affects lysosome function in human neurons, it could lead to a slow, gradual buildup of waste products in those cells. ALS usually affects cells of the motor cortex, which controls movement, and motor neurons in the spinal cord, while frontotemporal dementia affects the frontal areas of the brain’s cortex.
“If you cannot degrade things properly in cells that live for very long periods of time, like neurons, that might well affect the survival of the cells and lead to disease,” Corrionero says.
Many pharmaceutical companies are now researching drugs that would block the expression of the mutant C9orf72. The new study suggests certain possible side effects to watch for in studies of such drugs.
“If you generate drugs that decrease c9orf72 expression, you might cause problems in lysosomal homeostasis,” Corrionero says. “In developing any drug, you have to be careful to watch for possible side effects. Our observations suggest some things to look for in studying drugs that inhibit C9orf72 in ALS/FTD patients.”
The research was funded by an EMBO postdoctoral fellowship, an ALS Therapy Alliance grant, a gift from Rose and Douglas Barnard ’79 to the McGovern Institute, and a gift from the Halis Family Foundation to the MIT Aging Brain Initiative.
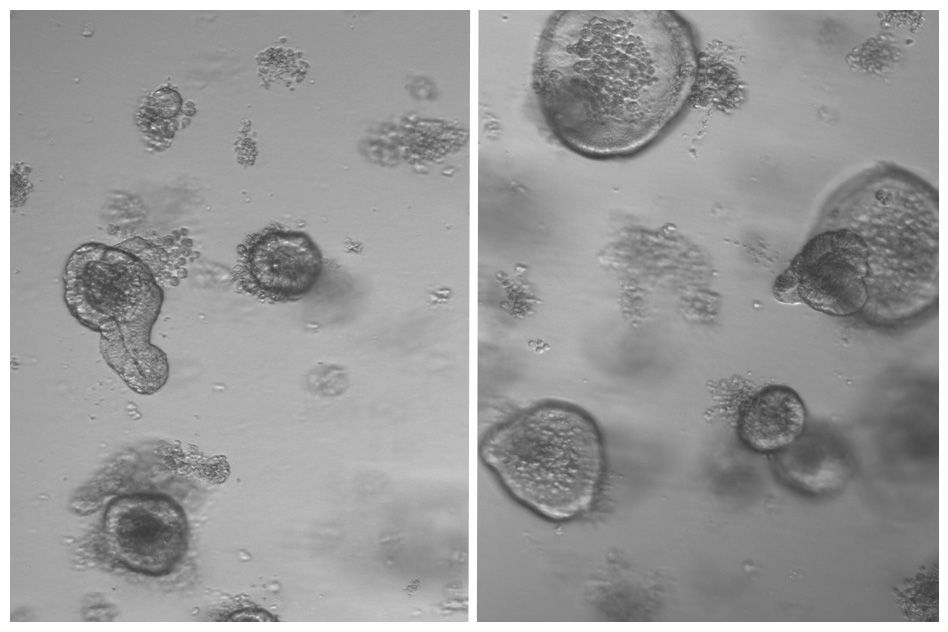
A drug treatment that mimics fasting can also provide the same benefit, study finds.
Anne Trafton | MIT News Office
May 1, 2018
As people age, their intestinal stem cells begin to lose their ability to regenerate. These stem cells are the source for all new intestinal cells, so this decline can make it more difficult to recover from gastrointestinal infections or other conditions that affect the intestine.
This age-related loss of stem cell function can be reversed by a 24-hour fast, according to a new study from MIT biologists. The researchers found that fasting dramatically improves stem cells’ ability to regenerate, in both aged and young mice.
In fasting mice, cells begin breaking down fatty acids instead of glucose, a change that stimulates the stem cells to become more regenerative. The researchers found that they could also boost regeneration with a molecule that activates the same metabolic switch. Such an intervention could potentially help older people recovering from GI infections or cancer patients undergoing chemotherapy, the researchers say.
“Fasting has many effects in the intestine, which include boosting regeneration as well as potential uses in any type of ailment that impinges on the intestine, such as infections or cancers,” says Omer Yilmaz, an MIT assistant professor of biology, a member of the Koch Institute for Integrative Cancer Research, and one of the senior authors of the study. “Understanding how fasting improves overall health, including the role of adult stem cells in intestinal regeneration, in repair, and in aging, is a fundamental interest of my laboratory.”
David Sabatini, an MIT professor of biology and member of the Whitehead Institute for Biomedical Research and the Koch Institute, is also a senior author of the paper, which appears in the May 3 issue of Cell Stem Cell.
“This study provided evidence that fasting induces a metabolic switch in the intestinal stem cells, from utilizing carbohydrates to burning fat,” Sabatini says. “Interestingly, switching these cells to fatty acid oxidation enhanced their function significantly. Pharmacological targeting of this pathway may provide a therapeutic opportunity to improve tissue homeostasis in age-associated pathologies.”
The paper’s lead authors are Whitehead Institute postdoc Maria Mihaylova and Koch Institute postdoc Chia-Wei Cheng.
Boosting regeneration
For many decades, scientists have known that low caloric intake is linked with enhanced longevity in humans and other organisms. Yilmaz and his colleagues were interested in exploring how fasting exerts its effects at the molecular level, specifically in the intestine.
Intestinal stem cells are responsible for maintaining the lining of the intestine, which typically renews itself every five days. When an injury or infection occurs, stem cells are key to repairing any damage. As people age, the regenerative abilities of these intestinal stem cells decline, so it takes longer for the intestine to recover.
“Intestinal stem cells are the workhorses of the intestine that give rise to more stem cells and to all of the various differentiated cell types of the intestine. Notably, during aging, intestinal stem function declines, which impairs the ability of the intestine to repair itself after damage,” Yilmaz says. “In this line of investigation, we focused on understanding how a 24-hour fast enhances the function of young and old intestinal stem cells.”
After mice fasted for 24 hours, the researchers removed intestinal stem cells and grew them in a culture dish, allowing them to determine whether the cells can give rise to “mini-intestines” known as organoids.
The researchers found that stem cells from the fasting mice doubled their regenerative capacity.
“It was very obvious that fasting had this really immense effect on the ability of intestinal crypts to form more organoids, which is stem-cell-driven,” Mihaylova says. “This was something that we saw in both the young mice and the aged mice, and we really wanted to understand the molecular mechanisms driving this.”
Metabolic switch
Further studies, including sequencing the messenger RNA of stem cells from the mice that fasted, revealed that fasting induces cells to switch from their usual metabolism, which burns carbohydrates such as sugars, to metabolizing fatty acids. This switch occurs through the activation of transcription factors called PPARs, which turn on many genes that are involved in metabolizing fatty acids.
The researchers found that if they turned off this pathway, fasting could no longer boost regeneration. They now plan to study how this metabolic switch provokes stem cells to enhance their regenerative abilities.
They also found that they could reproduce the beneficial effects of fasting by treating mice with a molecule that mimics the effects of PPARs. “That was also very surprising,” Cheng says. “Just activating one metabolic pathway is sufficient to reverse certain age phenotypes.”
Jared Rutter, a professor of biochemistry at the University of Utah School of Medicine, described the findings as “interesting and important.”
“This paper shows that fasting causes a metabolic change in the stem cells that reside in this organ and thereby changes their behavior to promote more cell division. In a beautiful set of experiments, the authors subvert the system by causing those metabolic changes without fasting and see similar effects,” says Rutter, who was not involved in the research. “This work fits into a rapidly growing field that is demonstrating that nutrition and metabolism has profound effects on the behavior of cells and this can predispose for human disease.”
The findings suggest that drug treatment could stimulate regeneration without requiring patients to fast, which is difficult for most people. One group that could benefit from such treatment is cancer patients who are receiving chemotherapy, which often harms intestinal cells. It could also benefit older people who experience intestinal infections or other gastrointestinal disorders that can damage the lining of the intestine.
The researchers plan to explore the potential effectiveness of such treatments, and they also hope to study whether fasting affects regenerative abilities in stem cells in other types of tissue.
The research was funded by the National Institutes of Health, the V Foundation, a Sidney Kimmel Scholar Award, a Pew-Stewart Trust Scholar Award, the Kathy and Curt Marble Cancer Research Fund, the MIT Stem Cell Initiative through Fondation MIT, the Koch Institute Frontier Research Program through the Kathy and Curt Marble Cancer Research Fund, the American Federation of Aging Research, the Damon Runyon Cancer Research Foundation, the Robert Black Charitable Foundation, a Koch Institute Ludwig Postdoctoral Fellowship, a Glenn/AFAR Breakthroughs in Gerontology Award, and the Howard Hughes Medical Institute.